
You’ve probably heard of RAG (Retrieval-Augmented Generation) by now, but might not know what it is or how it works. RAG expands the knowledge of large language models (LLMs) from their initial training data to external datasets you provide. If you want to build a chatbot or AI Agent, but you want it to give expert answers for your business context, you want RAG.
RAG extends the chatbot’s ability to give users immediate access to accurate, real-time, and relevant answers. So when one of your employees or customers asks your LLM a question, they get answers trained on your secure business data.
Instead of paying to finetune the LLM, which is time consuming and expensive, you can build RAG pipelines to get these kinds of results faster:
- LLMs that answer complex questions: RAG allows LLMs to tap into external knowledge bases and specific bodies of information to answer challenging questions with precision and detail.
- LLMs that generate up-to-date content: By grounding outputs in real-world data, RAG-powered LLMs can create more factual and accurate documents, reports, and other content.
- Increase LLM response accuracy: RAG augments answer generation with real-time data that’s relevant to your industry, customers, and business – so your chatbot is less likely to hallucinate to fill in missing information.
What is RAG?
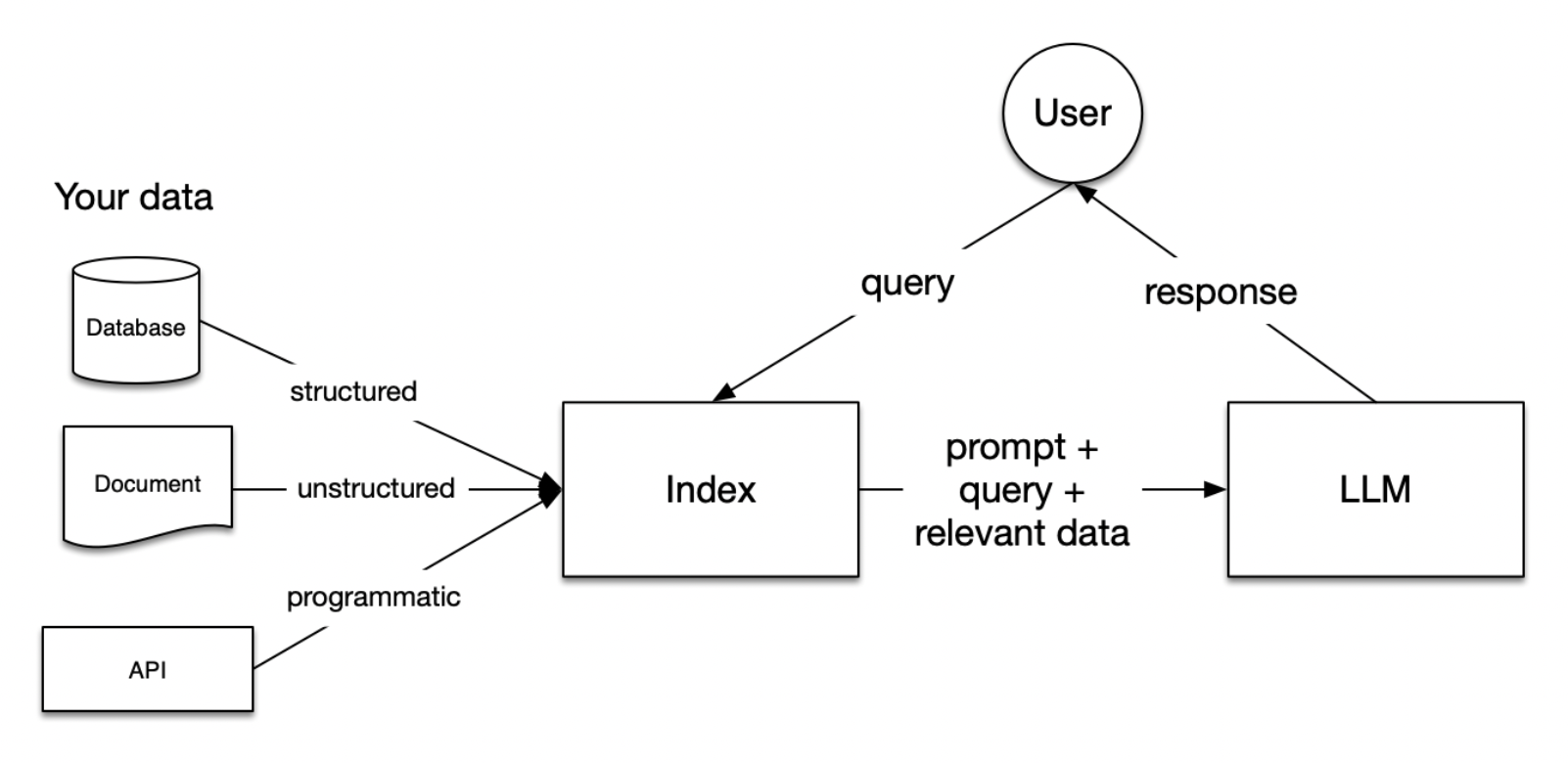
(RAG Diagram via OpenAI Cookbook)
RAG (retrieval-augmented generation) is a method to improve LLM response accuracy by giving your LLM access to external data sources.
Your LLMs are trained on enormous data sets, but they don’t have specific context for your business, industry, or customer. RAG adds that crucial layer of information. For example, you would add RAG to your internal LLM so that employees can access a secure company or department dataset.
Here’s a simple explanation of how RAG works.
RAG works in three stages:
1. Retrieval: Someone queries the LLM and the system looks for relevant information that informs the final response.
It searches through an external dataset or document collection to find relevant pieces of information. This dataset could be a curated knowledge base, a set of web pages, or any extensive collection of text, images, videos, and audio.
2. Augmentation: The input query is enhanced with the information retrieved in the previous step.
The relevant information found during the retrieval step is combined with the original query. This augmented input is then prepared for the next stage, ensuring that it is in a format suitable for the generation model.
3. Generation: The final augmented response or output is generated. Your LLM uses the additional context provided by the augmented input to produce an answer that is not only relevant to the original query but enriched with information from external sources.
Together, these three stages enable RAG-enhanced LLMs to produce responses that are more accurate, detailed, and contextually aware than what a standalone generative model can achieve.
But … RAG pipelines are complicated
We won’t go into every detail, like the original research on RAG does, but it’s helpful to break the three stages of RAG pipelines above into five different workflows.
- Loading: This involves importing your data into the RAG pipeline – e.g. text files, PDFs, websites, databases, APIs, etc. LlamaHub offers an extensive array of connectors for this purpose.
- Indexing: At this stage, you're developing a data structure conducive to data querying. For Large Language Models (LLMs), this typically involves generating vector embeddings, which are numerical representations of your data's meaning.
- Storing: After indexing your data, the next step is to store the index along with any additional metadata. This is crucial to eliminate the necessity for re-indexing in the future.
- Querying: Depending on your chosen indexing strategy, there are numerous methods to utilize LLMs and LlamaIndex data structures for querying. These methods range from sub-queries and multi-step queries to hybrid approaches.
- Evaluation: An indispensable part of any RAG pipeline is to assess its effectiveness. This could be in comparison to other strategies or following any modifications. Evaluation offers objective metrics to gauge the accuracy, reliability, and speed of your responses to queries.
Watch this video from LlamaIndex if you want a deeper technical dive right now.
We’re going to skip ahead and get into why RAG really matters – the business benefits and use cases.
Choose the right type of RAG
RAG has evolved far beyond simple vector search and retrieval. Multiple specialized RAG architectures have emerged, each optimized for different use cases and data types. Understanding these variations helps you choose the right approach for your specific business needs.
Baseline RAG
Traditional RAG uses vector similarity search to retrieve relevant text chunks from your knowledge base, converts queries and documents into embeddings, finds similar chunks, and feeds them to the LLM.
Best for: Simple question-answering and straightforward document retrieval where context is in individual text chunks.
Limitations: Baseline RAG struggles to connect the dots when answering questions requires traversing disparate pieces of information through their shared attributes.
GraphRAG
Microsoft released GraphRAG in mid-2024, using knowledge graphs instead of vector similarity by combining text extraction, network analysis, and LLM prompting. It combines vector search with structured taxonomies and ontologies, boosting search precision to as high as 99%.
GraphRAG outperforms baseline RAG with 70-80% win rates on comprehensiveness when answering abstract questions requiring holistic dataset understanding.
Best for: Legal research, healthcare diagnostics, financial analysis, and domains requiring reasoning over structured relationships.
Agentic RAG
Agentic RAG embeds autonomous AI agents into the RAG pipeline that employ iterative refinement and adaptive retrieval strategies. These agents leverage reflection, planning, tool use, and multi-agent collaboration to dynamically manage retrieval strategies
Agents independently evaluate query complexity, determine whether retrieval is needed, select optimal strategies, and validate their own results Unlike traditional RAG's one-time retrieval, Agentic RAG retrieves more information when needed, thinks step by step, and refines responses for better accuracy
Best for: Financial analysis, medical research, legal review, and tasks requiring understanding, synthesizing, and delivering meaningful insights
Multimodal RAG
The next generation of RAG integrates multimodal retrieval of images, videos, structured data, and live sensor inputs rather than focusing primarily on text Systems like ColPali process document pages as images, capturing visual layouts, tables, figures, and fonts that traditional text-based RAG misses
ColPali achieves state-of-the-art results while being drastically simpler, faster, and end-to-end trainable than traditional pipelines Patches retain the document's visual structure including spatial layout, font styles, and positional awareness
Applications: Medical AI analyzing scans alongside patient records, financial AI cross-referencing market reports with real-time trading data, and industrial AI integrating sensor readings for predictive maintenance
Best for: Financial reports, legal documents with complex formatting, research papers with figures, and any visually rich documents where layout carries semantic meaning.
We're entering an era where RAG becomes one tool in a broader toolkit, combining specialized training, sophisticated retrieval, and optimization techniques. The most effective systems often combine multiple approaches.
Now let’s get into why RAG really matters – the business benefits and use cases.
Business benefits of RAG
Imagine a customer service representative who needs to answer a complex question about a product. Normally, they’d have to sort through multiple documents, product listings, and customer reviews to come up with their own answer. It could take ten minutes, an hour, or until the next day to return a solid answer for the customer.
With RAG, your reps can ask the company LLM a product question and receive a comprehensive answer that is automatically sourced from relevant product manuals, FAQs, customer reviews, sizing charts, inventory data, and other documents. This could take seconds.
Similar improvements are possible across your other internal processes and customer-facing experiences.
Enhanced accuracy and reliability
- Factual and well-sourced content: RAG ensures that LLM outputs are grounded in real-world data – leading to more accurate and reliable results.
- Reduced bias and errors: By accessing verified information, RAG helps to mitigate the risk of bias and errors in LLM outputs.
- Improved user trust: The ability to trust the information provided by LLMs increases user confidence and adoption.
Increased productivity and efficiency
- Faster access to information: RAG empowers users to quickly retrieve relevant information without having to sift through large volumes of data.
- Improved decision-making: Access to accurate and up-to-date information allows users to make more informed decisions faster.
- Reduced workload: Automating knowledge-intensive tasks frees up valuable time for employees to focus on more strategic initiatives.
Better experiences and cost savings
- Reduced LLM training costs: RAG can help to reduce the need for expensive fine-tuning of LLMs, as they can access the necessary information dynamically.
- Improved resource utilization: By helping to automate tasks, RAG-based systems can free up valuable IT resources for other purposes.
- Enhanced customer experience: RAG-powered applications can provide customers with the information they need quickly and efficiently – leading to increased satisfaction.
Build production-ready RAG applications
It’s easy to build a simple RAG pipeline from tutorials you find online. But, production-ready enterprise RAG applications are a different beast.
If you want to know more watch this video on production-ready RAG applications.
The speaker, Jerry Liu, is a co-founder and CEO of LlamaIndex. In the video, he discusses the current RAG stack for building a QA system, the challenges with naive RAG, and how to improve the performance of a retrieval augmented generation application. He also talks about evaluation and how to optimize your RAG systems.
Here are some key points from the video:
- The challenges with naive RAG include bad retrieval issues, low recall, and outdated information.
- To improve the performance of a retrieval augmented generation application, you can optimize the data, the retrieval algorithm, and the synthesis.
- Evaluation is important because you need to define a benchmark for your system to understand how you are going to iterate on and improve it.
- There are a few different ways to evaluate a RAG system – including retrieval metrics and synthesis metrics.
- When optimizing your RAG systems, you should start with the basics, such as better chunking and metadata filtering.
- More advanced techniques include reranking, recursive retrieval, and agents.
- Fine-tuning can also be used to improve the performance of a RAG system. This can be done by fine-tuning the embeddings, the base model, or an adapter on top of the model.
LlamaIndex is just one of many popular tools you can use in RAG architecture.
Best tools to build RAG solutions
The choice of tools largely depends on the specific needs of your RAG implementation – e.g. the complexity of the retrieval process, the nature of the data, and the desired output quality.
For example, Langchain and LlamaIndex are popular entry points to RAG technology but developers have preferences between the two. And many have given up on using Langchain or LlamaIndex at all to simplify their own designs.
Here's a short list of some of the best tools for RAG:
-
Microsoft GraphRAG: Open-source graph-based RAG system combining text extraction, network analysis, and LLM summarization for knowledge graph-based retrieval.
-
ColPali (via Byaldi): Vision language model for multimodal document retrieval, processing document pages as images to preserve visual layouts and formatting.
- Hugging Face RAG Transformer: Provides a comprehensive collection of pre-trained models, including RAG.
- Vellum.ai: Vellum is a development platform for building LLM apps with tools for prompt engineering, semantic search, version control, testing, and monitoring.
- Elasticsearch: A powerful search engine, ideal for the retrieval phase in RAG.
- FAISS (Facebook AI Similarity Search): Efficient for similarity search in large datasets, useful for retrieval.
- Haystack: An NLP framework that simplifies the building of search systems, integrating well with Elasticsearch and DPR.
- PyTorch and TensorFlow: Foundational deep learning frameworks for developing and training RAG models.
- ColBERT: A BERT-based ranking model for high-precision retrieval.
- Apache Solr: An open-source search platform, an alternative to Elasticsearch for retrieval.
- Pinecone: A scalable vector database optimized for machine learning applications.Ideal for vector-based similarity search, playing a crucial role in the retrieval phase of RAG.
Here's a full article on the best RAG tools and techniques – from vector databases to RAG eval tools.
Choosing your RAG stack
The RAG tooling ecosystem has expanded dramatically. For production systems, consider:
- Baseline RAG: LangChain/LlamaIndex + Pinecone/Qdrant + standard embedding models
- GraphRAG: Microsoft GraphRAG + Neo4j or similar graph databases
- Agentic RAG: LangGraph + multiple data source connectors + function-calling LLMs
- Multimodal RAG: ColPali/Byaldi + vision language models + multi-vector databases
Ultimately, if you want RAG-based LLMs you need senior software engineers who’ve been working with these RAG tools and technologies closely. It’s very new and everyone is still learning how to optimize RAG.
Use cases for building RAG
Any internal workflow or external customer-facing experience that requires data specific to your business could potentially be improved by RAG. Different RAG architectures excel in different scenarios, and 2025 has shown measurable business impact across industries.
Enterprise knowledge management
- Cross-system intelligence: Enterprise RAG gives AI direct access to internal systems, so information isn't frozen in time – updating policy as company rules change, complying with the latest regulations, and adjusting product details to inventory and pricing.
- Agentic research assistants: Deploy autonomous agents that can conduct comprehensive research across multiple internal data sources, synthesizing information from documents, databases, and real-time systems.
Customer service RAG use cases
- Expert chatbots: RAG empowers chatbots to answer complex questions and provide personalized support to customers – improving customer satisfaction and reducing support costs.
- Knowledge base search: Quickly retrieve relevant information from internal knowledge bases to answer customer inquiries faster and more accurately.
- Personalized recommendations: A leading online retailer saw a 25% increase in customer engagement after implementing RAG-driven search and product recommendations that analyze real-time inventory, user reviews, and dynamic pricing data.
Legal industry RAG use cases
- Legal research with GraphRAG: Efficiently search and retrieve relevant legal documents, case law, and other legal materials while understanding relationships between cases and precedents to save lawyers valuable time and resources.
- Contract review and drafting: Automate the review and drafting of legal contracts to ensure accuracy and compliance with legal requirements.
- Document analysis with multimodal RAG: Process visually complex legal documents containing tables, signatures, and formatting that traditional text extraction misses.
Healthcare RAG use cases
- Real-time medical information: RAG-powered AI transforms healthcare by integrating real-time diagnostic data, drug interactions, and the latest clinical research, ensuring medical decisions are based on current information rather than outdated training data.
- Medical diagnosis and treatment plans: Assist physicians in diagnosing diseases and recommending treatment plans based on patient symptoms and medical history.
- Multimodal medical analysis: Medical AI can analyze scans alongside patient records, combining visual and textual information for more comprehensive assessments.
- Drug discovery: Analyze large datasets of scientific literature and patient data to identify promising drug candidates for further research.
Manufacturing RAG use cases
- Predictive maintenance with multimodal RAG: Industrial AI integrates sensor readings for predictive maintenance, predicting machine failures before they occur to reduce downtime and maintenance costs.
- Quality control: Automate quality control processes by identifying defects in products using image recognition and other AI techniques.
- Supply chain optimization: Optimize supply chains by identifying and predicting potential disruptions to increase efficiency and cost savings.
Finance RAG use cases
- Real-time market analysis: Financial markets change by the second, so static AI models are unreliable – RAG allows AI to retrieve real-time market data, regulatory changes, and trading information before generating responses.
- Complex financial document analysis: Financial AI can cross-reference market reports with real-time trading data, while multimodal RAG processes quarterly reports, balance sheets, and regulatory filings containing complex tables and charts.
- Fraud detection: Identify fraudulent transactions in real-time to protect financial institutions and customers from risk and losses.
- Agentic analysis: Use autonomous agents to conduct multi-step financial analysis, comparing performance across time periods and against industry benchmarks.
Education RAG use cases
- Personalized learning: Create personalized learning plans for students based on their individual needs and learning styles.
- Automated grading: Automate grading of essays and other assessments to free up educators' time to focus on providing personalized feedback to students.
- Adaptive learning systems: Develop adaptive learning systems that adjust the difficulty of the learning material based on the student's progress and understanding.
New use cases continue to emerge as RAG architectures mature. The key is matching your business needs to the right RAG approach – whether that's the simplicity of baseline RAG, the relationship reasoning of GraphRAG, the autonomy of Agentic RAG, or the visual understanding of multimodal systems.
How do I hire a team to build RAG for LLMs?
Instead of waiting 6-18 months to recruit senior engineers, you could engage Codingscape experts who’ve been busy building RAG-based applications for our partners. We can assemble a senior RAG development team for you in 4-6 weeks.
It’ll be faster to get started, more cost-efficient than internal hiring, and we’ll deliver high-quality results quickly. Zappos, Twilio, and Veho are just a few companies that trust us to build their software and systems with a remote-first approach.
You can schedule a time to talk with us here. No hassle, no expectations, just answers.
